



MFR-DTA:用于预测药物-靶标结合亲和力和区域的多功能鲁棒模型

1 介绍:
药物-靶点相互作用(DTI)预测对于药物发现至关重要,计算机辅助DTI已成为该任务最流行和最有效的方法。通常,DTI预测被表述为二元分类任务,然而使用二元标签(0 或 1)来定量反映交互强度具有挑战性。为了弥合这一差距,Tang 等人首先将DTI预测视为回归任务,后He等人提出了预测药物-靶标结合亲和力(DTA)的概念。尽管大多数现有的DTI和DTA预测方法都取得了可喜的结果,但它们并非没有问题。一方面,主流的生物序列特征提取方法在提取丰富的蛋白质和药物特征方面存在不足:(1)1D卷积和MLP都完全忽略了每个元素的单独特征。(2)LSTM和GNN直接提取单独特征,但不足以获取全局特征。(3)2D卷积通过增加卷积核或卷积层来提取单独和全局特征,但其计算消耗大。另一方面,许多现有方法尝试通过注意力机制来提高表现。然而,这些方法试图通过高注意力响应来识别BR(相互作用结合区域),这很难验证,也缺乏理论基础,因为突出显示的区域与蛋白质的生物学特征无关。
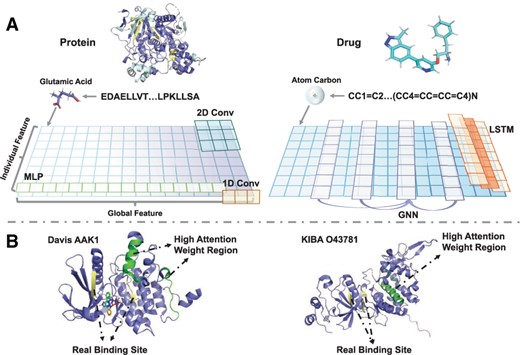
图1 现有方法存在的两个主要问题 (A)现有分子特征提取方法的感受野 (B)预测注意力权重权重和实际结合位点差异的两个实例
为了缓解上述问题,本文提出了一种多功能稳健的药物-靶标结合亲和力预测模型MFR-DTA,该模型有三个主要创新:(1)BioMLP/CNN块用于丰富的蛋白质和药物特征提取,为了同时提取序列中单个元素的个体特征和关联特征,率先提取了生物序列元素的个体特征。(2)元素特征融合块用于有效的特征挖掘,蛋白质和药物的特征由两种形式表述,通过特征融合有效地维护两方面的核心信息。(3)混合解码块有效提取DTI特征并同时预测其BR。
2 方法:
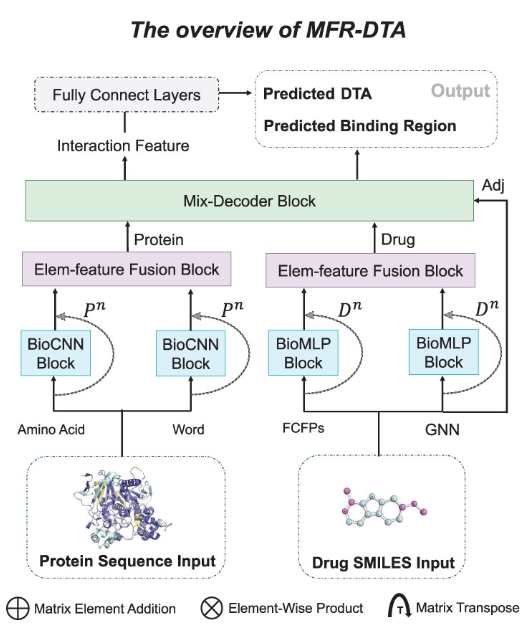
图2 MFR-DTA整体架构
所提出的MFR-DTA方法包括三个主要模块:BioMLP/CNN、Elem-feature fusion和Mix-Decoder。此外,MFR-DTA使用全连接层,通过Mix-Decoder模块提取的交互特征来预测DTA。
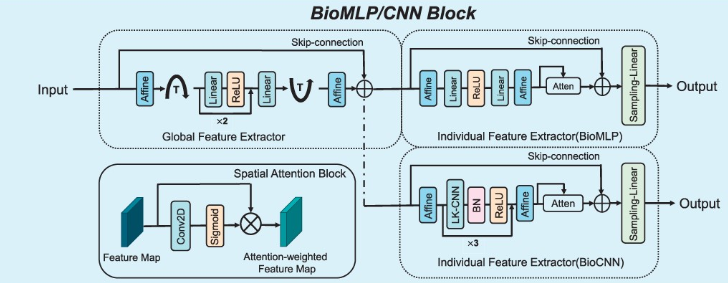
图3 BioMLP/CNN模块结构
(1)BioMLP/CNN模块: 采用两个子模块——全局特征提取器和个体特征提取器来提取药物和蛋白质的全局特征和个体特征。首先,使用全局特征提取器来提取不 同生物序列的相关性,由仿射块、全连接层和 ReLU 激活层组成: 。其次,使用两个单独的特征提取器来进一步挖掘生物序列组成信息,根据输出的全局特征,作为组成元素的个体特征:
。其次,使用两个单独的特征提取器来进一步挖掘生物序列组成信息,根据输出的全局特征,作为组成元素的个体特征:
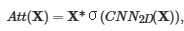 通过二维卷积捕获相邻元素间的局部关系。最后,BioMLP/CNN模块通过加法操作将全局特征和个体特征组合在一起,并使用全连接层获得全面且具有代表性的特征。具体而言,BioMLP使用更少的线性层来提取个体特征,适用于较短的生物序列,例如药物序列。相比之下,BioCNN使用更多的大核卷积层,可以有效地提取复杂序列的特征,如蛋白质序列。
通过二维卷积捕获相邻元素间的局部关系。最后,BioMLP/CNN模块通过加法操作将全局特征和个体特征组合在一起,并使用全连接层获得全面且具有代表性的特征。具体而言,BioMLP使用更少的线性层来提取个体特征,适用于较短的生物序列,例如药物序列。相比之下,BioCNN使用更多的大核卷积层,可以有效地提取复杂序列的特征,如蛋白质序列。
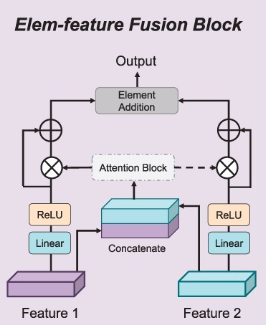
图4 Elem-feature Fusion模块结构
(2)Elem-feature Fusion模块: 采用氨基酸嵌入AAE和词嵌入WE表示蛋白质特征,采用FCFP指纹和GCN特征表示药物特征。为了丰富精细特征的语义信息,平衡不同特征类型的贡献,提出了一个融合块,将特征矩阵转换为融合特征矩阵: 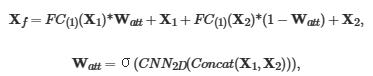 1 的注意力权重矩阵W att ,并将X 2 特征的注意力权重设为1-W att ,以促进两种类型的特征能够互补。
1 的注意力权重矩阵W att ,并将X 2 特征的注意力权重设为1-W att ,以促进两种类型的特征能够互补。
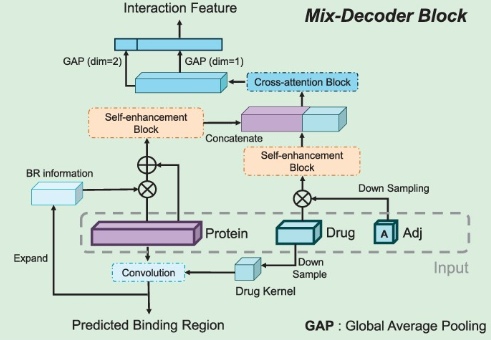
图5 Mix-Decoder模块结构
(3)Mix-Decoder模块: 混合解码器输入包括精制药物特征、精制蛋白质特征和药物Adj矩阵。为了预测药物靶标BRs,首先对药物下采样获得药物核,再将药物核与蛋白质特征卷积得到响应向量 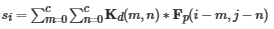 ,其中高值区域为BRs。为了提取DTI特征,首先将响应向量s通过重复填充扩充为BR信息矩阵,再与蛋白质特征矩阵相乘进行加权,以鼓励模型关注BR信息,通过元素加法得到精制蛋白质特征;然后融合药物邻接矩阵信息丰富药物特征,通过全局平均池化将Adj矩阵下采样为原子连通性向量,再将连通性向量通过重复填充扩展为 Adj信息矩阵,与药物特征进行元素乘法得到精制药物特征;再通过自增强块SE增强药物和蛋白质特征
,其中高值区域为BRs。为了提取DTI特征,首先将响应向量s通过重复填充扩充为BR信息矩阵,再与蛋白质特征矩阵相乘进行加权,以鼓励模型关注BR信息,通过元素加法得到精制蛋白质特征;然后融合药物邻接矩阵信息丰富药物特征,通过全局平均池化将Adj矩阵下采样为原子连通性向量,再将连通性向量通过重复填充扩展为 Adj信息矩阵,与药物特征进行元素乘法得到精制药物特征;再通过自增强块SE增强药物和蛋白质特征 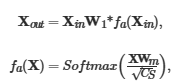 中fa()增强了特征矩阵 X中 对模型性能有显著影响的区域;最后通过交叉注意力模块 CA提取 相互作用特征
中fa()增强了特征矩阵 X中 对模型性能有显著影响的区域;最后通过交叉注意力模块 CA提取 相互作用特征 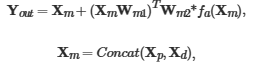 。
。
3 结果:
表1 基准数据集的统计数据
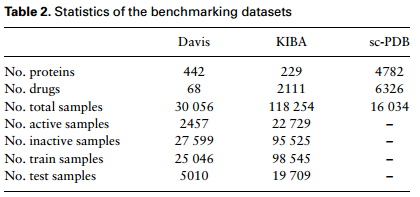
(1) 评估数据集和指标: 为了与DeepDTA保持一致,在两个基准Davis和KIBA上评估了模型,通过五倍交叉验证,将训练样本进一步分为训练集和验证集。此外,将新的3D数据集sc-PDB的数据转换为序列格式,以评估所提出的BR预测方法的性能。使用一致性指数CI、MSE、r 2 m 指数和准确率-召回率曲线AUPR下面积指标来评估所提出的模型,其中,为了合理地测量AUPR,通过选择结合亲和阈值将定量数据集转换为二进制数据集,对于Davis数据集使用阈值7,对于KIBA数据集使用阈值12.1。
(2) 消融研究: 首先分析了MFR-DTA中每个创新模块的有效性。然后研究了不同的蛋白质特征选择方法。最后将所提出的Mix-Decoder模块与其他交互特征提取方法进行了比较。
表2 在 KIBA 和 Davis 数据集上获得的消融研究结果
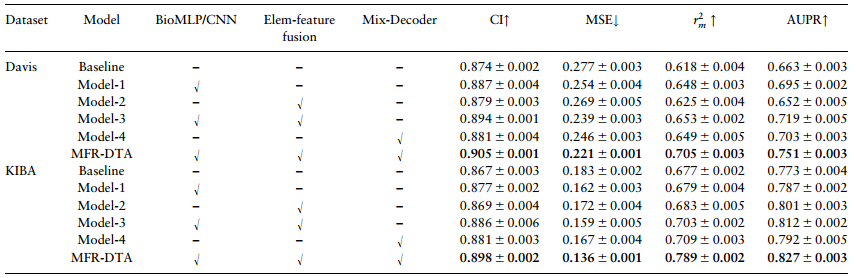
①不同创新要素分析: 将CPInformer作为基线方法,它通过WE表示蛋白质一级结构序列并使用分子特征融合模块来融合和细化药物的FCFPs和GCN特征,然后通过Informer模型进行DTI特征提取。在本文中,通过添加 BioMLP/CNN、Elem-feature Fusion和Mix-Decoder 模块来改进基线方法。可以看出Model-1提高了基线方法的性能,因为所提出的BioMLP/CNN模块提取了更全面的特征(包括个体和全局特征);Model-2的结果说明所提出的Elem-feature Fusion模块可以更好地融合药物和蛋白质特征。此外,在MSE方面,Model-4实现了进一步的提升,该结果初步证明了Mix-Decoder模块的效率,将在后文中进一步讨论该模块的主要贡献。
表3 比较不同的蛋白质特征提取和融合方法
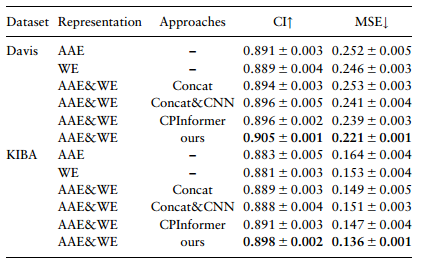
②不同蛋白质特征表示和融合方法分析:CPInformer已经证明图特征和指纹特征的融合优于单一使用。为了进一步阐明本文的设计,分析了不同蛋白质特征表示和融合方法的有效性。使用两种蛋白质特征表示,包括AAE和WE,AAE的生物学特性有助于所提出的模型预测亲和力趋势,使其在CI指标方面表现更好;相比之下,WE特征提取方法提供了更多的语义信息,鼓励模型在MSE收敛并表现更好。为了验证模型在引入这两种表征时是否表现更好,采用四种不同的融合方法将上述两种特征结合起来,并细化蛋白质和药物特征,可以看出两个融合特征的性能优于单个融合特征,进一步证明了两种蛋白质特征表示可以相互补充。此外,所提出的特征融合模块在两个基准测试中的两个指标上都证明了其优于其他三种方法,证明了其良好的特征融合能力。
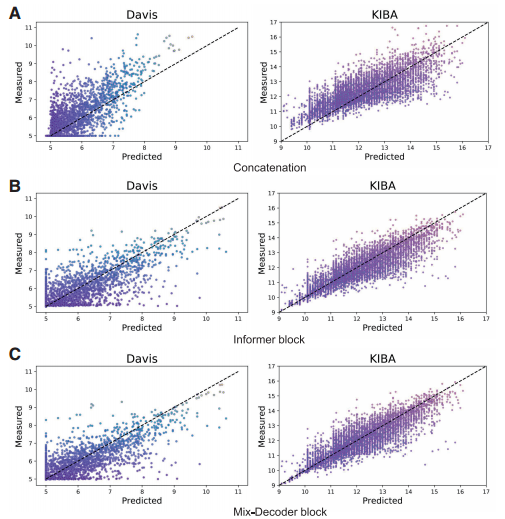
图6 三种交互方式的表现

图7 Mix-Decoder中主要组件对模型性能的影响
③不同交互特征提取方法分析: 比较了串联、CPInformer中基于注意力的Informer模块和本文提出的Mix-Decoder模块,从散点图中可以看出三种方法的散射适度集中在对角线上,而Mix-Decoder模块的散射则更集中。进一步分析了Mix-Decoder中涉及的主要组件,可以看出S-E和C-A模块的同时采用可以提高模型性能,且药物邻接矩阵信息和BR信息二者的融合有助于模型性能提升。
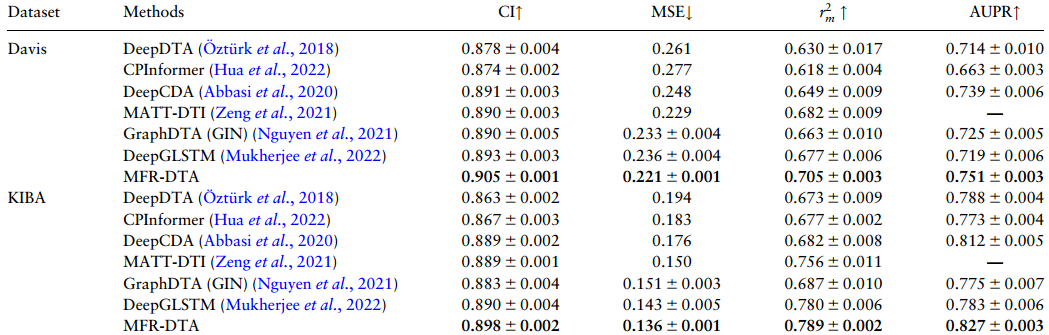
(3) 与先进方法比较: 将所提出的MFR-DTA方法与现有的主流DTA预测模型进行了比较,在两个数据集上获得的实验表明,在所有评估指标方面几乎优于所有其他方法。
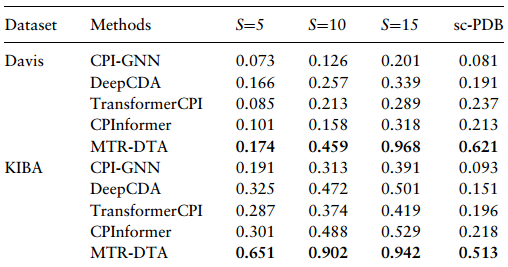
(4) 药物靶点BR预测的可视化: 将MFR-DTA与预测药物靶标BR的现有方法进行了比较,以实际结合位点落入预测区域的概率作为衡量这些方法准确性的指标。S为预测区域氨基酸长度,其中点是药物-靶标响应向量中值最高的位置。虽然方法整体的效果一般,但仍可以看出MFR-DTA的性能最佳。
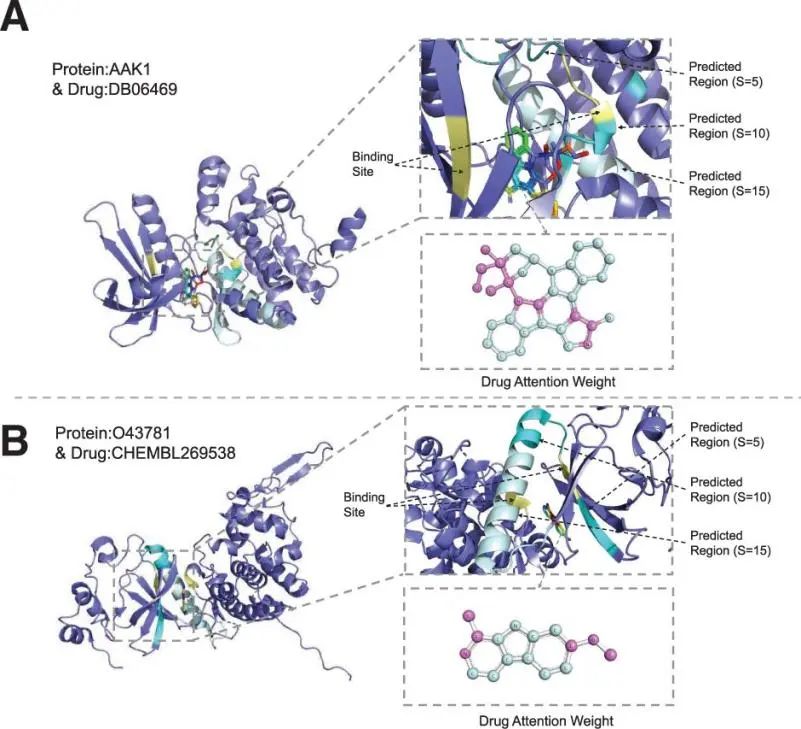
图8 在两个样本对中三个尺度和结合位点上预测的 BR 的可视化
再次对第1节中提出的测试样品进行了可视化,以进一步证明所提出方法的有效性。在这部分中,蓝紫色区域是非相互作用区域。浅蓝色、蓝色和深蓝色区域分别是 S=15、10 和 5 的预测区域。黄色位置是实际的结合位点。虽然蛋白质“AAK1”的预测相对偏差,但其结合位点也落在有鳞片的区域,而蛋白质“O43781”的结合位点准确地落入了具有尺度的预测区域,这直观地展示了本文提出的预测BR方法的优异性能。同时,根据SE模块的特征公式fa参数可视化药物分子,其中粉红色区域代表较高的注意力权重。不幸的是,与其他方法类似,这种可视化只反映了计算机的注意力,没有任何生物医学意义。
4 结论:
提出了一种新颖的MFR-DTA方法,可以同时预测DTA和BR区域。首先通过BioMLP/CNN模块提取生物序列特征,整合单个元素特征和全局位置特征;然后通过Elem-feature融合块对提取的特征进行融合和细化;之后开发了 Mix-Decoder来提取用于BR预测的DTI特征;最后通过将全连接层应用于交互特征来预测 DTA。在三个数据集上获得的实验结果验证了MFR-DTA方法优于其他最先进的方法。然而,作者认为该方法仍存在其问题,它对药物分子的可视化仍然基于注意力权重。因此,在未来的DTA预测研究中,应进一步探索药物分子作用于蛋白质的结构因素,以继续提高DTA模型的生物学可解释性。
链接:http://www.lewenyixue.com/2024/04/26/MFR-DTA%EF%BC%9A%E7%94%A8%E4%BA%8E%E9%A2%84%E6%B5%8B%E8%8D%AF%E7%89%A9-%E9%9D%B6%E6%A0%87%E7%BB%93%E5%90%88%E4%BA%B2/

赶快来坐沙发