浙大学者结合血浆蛋白质组学等,开发结直肠癌发病预测模型,发文Nature子刊,来看看过程与统计方法
202 4年10月15日, 浙江大学医学院附属第二医院学者团队在顶级 期刊 Nature 子刊 《Nature Communications》 (医学一区top,IF=14.7) 上发表了题为 “Plasma proteomic and polygenic profiling improve risk stratification and personalized screening for colorectal cancer” 的研究论文,旨在通过将蛋白质组学特征与遗传和非遗传因素(QCancer-15)相结合,确定结直肠癌(CRC)相关的蛋白质组学特征并开发CRC发病预测模型,以改善风险分层和个性化初始筛查年龄的估计。

如果你需要全文,请公众号后台回复关键词“ pdf”。如果您需要进一步的了解随机对照研究如何进行数据分析,不妨看看我们 临床试验设计与数据分析培训班! 详情可咨询助教,微信号:aq566665
-
首先基于病例对照研究和前瞻性人群队列的 两阶段策略 来识别和验证与CRC相关的蛋白质组学特征, 以构建蛋白质风险评分(ProS)。
-
构建了 QCancer-15风险评分、多基因风险评分(PRS) ,并结合关键的蛋白质生物标志物 开发CRC发病预测模型。
-
最后, 评估 联合模型的预测性能和潜在的临床效用,包括净收益、风险分层和 CRC 个性化初始筛查年龄。

结直肠癌(CRC)预测模型
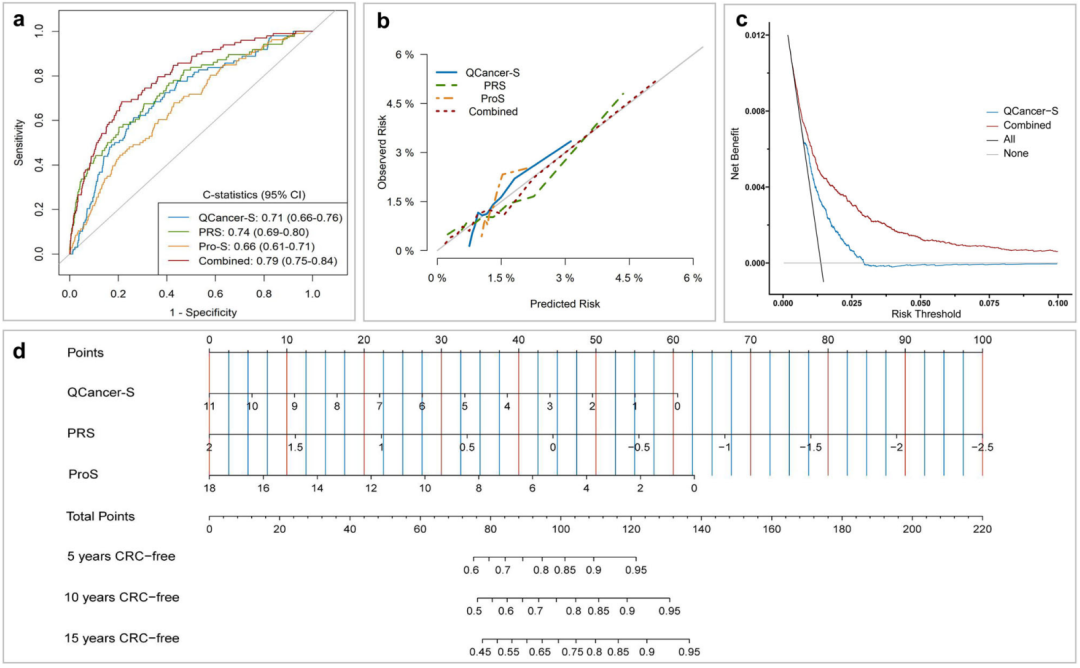
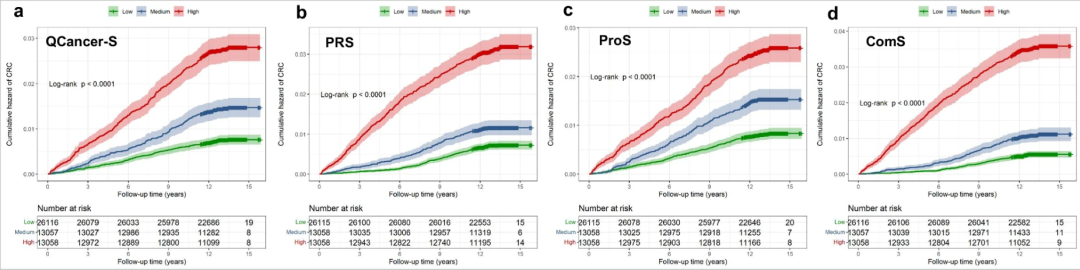
综合模型在风险分层方面表现出色
-
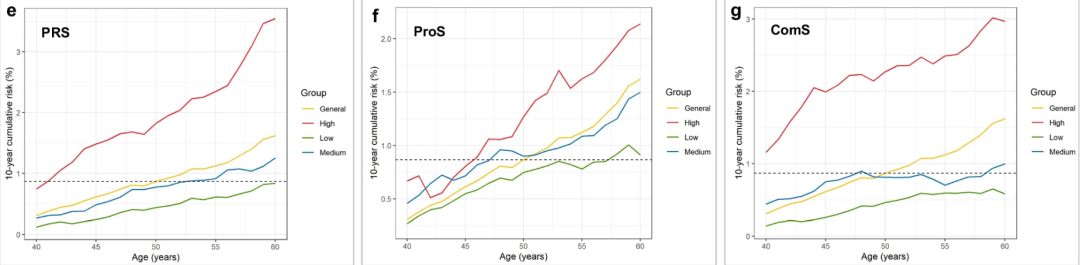
高PRS组的受试者应在41岁开始筛查,而低PRS组的筛查起始年龄为60岁以上;
-
高ProS组的受试者应在46岁开始筛查,而低ProS组的筛查起始年龄为57岁;
-
ComS显示,高风险组的受试者建议在40岁之前开始筛查,而低风险组则可推迟至60岁以后再进行筛查。
统计学方法
-
使用主成分分析和Pearson相关系数矩阵来识别异常样本(补充方法)
-
在去除异常样本后,基于‘ limma ’ package29进行蛋白质组级差异表达分析
-
采用FDR进行多重检验校正,以FDR < 0.05为显著性水平。
-
对于处于发现阶段的显著蛋白(FDR < 0.05),我们进一步采用 Cox 比例风险(CPH)模型 评估其与验证队列中CRC发病率的关系。

-
通过 LASSO-Cox回归 ,在通过两阶段测试的蛋白质中进一步选择了CRC相关蛋白质特征,总共保留15个蛋白质。
-
使用` caret `包,以 7:3的比例 将UKBB参与者随机分为训练和验证组。
-
基于QCancer-S、QCancer-S(包括地理区域)、2 prs或ProS分别建立结直肠癌风险预测模型,使用CPH模型在培训队列中进行五倍交叉验证。
-
接下来,将表现最佳的QCancer-S、ProS和PRS组合, 构建预测结直肠癌发病风险的联合模型。
-
这些模型还通过性别分层、肿瘤部位(结肠或直肠)、肠癌筛查(是否)和CRC家族史(是否)进行评估。
-
在训练队列中,采用 c统计量 (95%置信区间,CI)进行五倍交叉验证,并在验证队列中进一步评估这些模型的判别性。
-
采用自举法,采用500个分层自举重复,比较不同模型的性能差异。
-
使用“riskRegression”软件包绘制 校准曲线 ,以直观地描述基于CPH模型的观测事件率与预测风险之间的一致性。
-
建立QCancer-S、PRS和ProS的 列线图 ,用于预测5年、10年和15年无结直肠癌的预后。
-
为了评估预测模型对推荐的CRC干预措施(如筛查)的潜在临床效用,使用“ggDCA”包进行 决策曲线分析

4. 风险比估计及风险分层分析 :
-
HRs 首先通过CPH回归得出QCancer-S、PRS和ProS每SD增加的总体、性别特异性和部位特异性CRC风险。
-
然后,根据QCancer-S、PRS、ProS和ComS(补充方法)在当前UKBB人群中的分布,分别分为q1最低、Q2、Q3和q4最高的四分位数。
-
由于10年累积风险曲线 趋势相似 ,进一步将风险评分分为低、中、高3组(补充图9)。
-
具体而言,以普通人群10年累积风险为参照,将Q3中风险与普通人群相似的参与者划分为中风险组,将Q1和Q2中风险低于普通人群的参与者划分为低风险组。Q4的参与者被划分为高危组。
-
以中剂量组为参照,估计分类变量的hr (95% ci)。
-
采用 Kaplan-Meier曲线和log-rank检验 评估风险评分的风险分层值。

链接:http://www.lewenyixue.com/2024/10/21/%E6%B5%99%E5%A4%A7%E5%AD%A6%E8%80%85%E7%BB%93%E5%90%88%E8%A1%80%E6%B5%86%E8%9B%8B%E7%99%BD%E8%B4%A8%E7%BB%84%E5%AD%A6%E7%AD%89%EF%BC%8C%E5%BC%80%E5%8F%91%E7%BB%93%E7%9B%B4%E8%82%A0/