Genome Biol | 李亦学/王连生/高峰团队合作发表多组学预训练肿瘤多任务基础模型TMO-Net
近日,广州国家实验室的李亦学与厦门大学 王连生 、中山大学 高峰 教授团队在 Genome Biology 在线发表了肿瘤多组学数据人工智能研究的最新合作研究成果: TMO-Net: an explainable pretrained multi-omics model for multi-task learning in oncology 。 该研究提出了一个名为TMO-Net (Tumor Multi-Omics pre-trained Network) 的可解释肿瘤多组学预训练模型,整合泛癌多组学数据集进行模型预训练,通过跨组学交互和多模态自监督学习,实现癌症多组学数据的表征与缺失组学推断 。作为一个肿瘤研究的预训练基础模型 (pre-train foundation model) ,采用小样本对基础模型进行参数微调,TMO-Net展示了其深度融合多组学数据的能力与在不同肿瘤下游分析任务中的适用性,在癌症亚型分类、转移预测、药物反应预测、预后预测以及数据生成等任务中,TMO-Net性能优于现有的基线模型。该研究揭示了大规模肿瘤多组学数据预训练和基础模型技术在将来肿瘤研究中的重要潜力。
癌症的发生往往伴随着肿瘤抑制基因或原癌基因的异常调控,而这种异常调控会进一步导致系统性细胞改变和肿瘤细胞增殖与转移。高通量测序技术的快速发展,为解析肿瘤发生发展过程提供了重要的技术支撑,包括基因突变、基因表达等的一系列多组学数据为加深我们对癌症发病机制和进展过程的理解提供了重要的数据支持。此前已开发了多种用于整合多组学数据以预测特定临床问题的人工智能算法,此类方法大多依赖于特定的研究队列,在实际应用中面临“高维特征-小样本”和缺失模态等问题。因此,亟需一种通用的深度学习框架,能够有效整合大规模多组学癌症数据集,并确保缺失模态下不同肿瘤学任务的适用性。
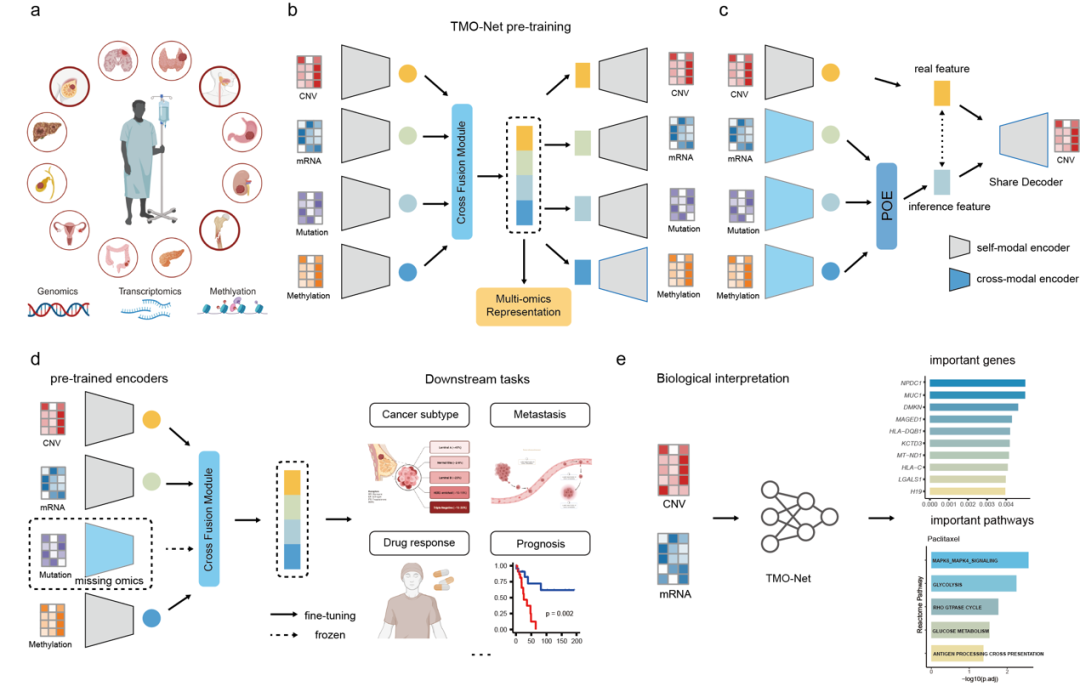 (模型框架示意图)
TMO-Net深度学习框架包括了单模态变分自编码器,跨模态变分自编码器,跨模态融合模块 (Cross Fusion Module) 。跨融合模块目的是将不同模态的嵌入融合到一个共同空间,通过使用专家乘积 (Product-of-Experts, PoE) 模块,有效地融合边缘变分后验的乘积并生成联合的潜在表征。在跨模态推断任务中,这些预训练得到的联合表征被用来重建缺失模态的数据,帮助实现样本的全模态表征。这一设计允许TMO-Net在面对缺失模态数据时仍能保持高效的样本表征学习和预测能力。作者从TCGA数据库中获取了32个泛癌多组学数据集,包含8174个样本,包含基因突变、mRNA表达、拷贝数变异 (CNV) 和DNA甲基化四种数据模态。在自监督预训练阶段,TMO-Net表现出了良好的肿瘤单/多组学样本表征能力和缺失数据的重构能力。在下游任务微调阶段,作者利用TMO-Net生成的多组学癌症样本表征,对模型参数进行微调以学习更加适应特定任务的表征,模型在多个下游肿瘤临床任务中展现了良好的适用性,包括乳腺癌亚型分类、癌症原发性与转移性预测、药物反应预测和癌症预后预测。
此外,作者还利用深度学习梯度归因算法 (Integrated Gradients) 来解释不同组学数据特征对肿瘤下游任务的影响。在乳腺癌亚型分类中,作者识别了 TM4SF5 、 RERG 、 NKX2-1 和 ESR1 等在乳腺癌分化、进展和癌症代谢起到重要作用的基因。在肿瘤转移分析中,研究人员确定了 TMC6 基因在肿瘤转移中的关键作用,并揭示了位于 KCNQ1 基因组区域的特定CpG探针:cg26879282、cg20751395和cg16778148对肿瘤转移的作用。作者还进一步探讨了 EGFR 基因表达在不同EGFR抑制剂药物的疗效的关联,以及不同基因特征对肿瘤预后的影响。该研究表明深度学习可解释性方法是进一步利用肿瘤人工智能模型进行疾病靶点解析的重要工具。
综上,该研究提出的TMO-Net模型框架证明了在大规模肿瘤多组学数据集上进行预训练可以增强肿瘤多组学和缺失组学数据的表征学习能力。该研究为未来开发生命科学多组学大模型奠定了基础,代表了肿瘤多组学数据人工智能研究领域的新进展。
中国科学院大学杭州高等研究院博士生、广州国家实验室实习生王烽傲、厦门大学硕士生庄震丰、中山大学第六附属医院高峰副研究员为该论文的共同第一作者。广州国家实验室李亦学研究员、刘俊伟博士后与厦门大学王连生教授为该论文的共同通讯作者。该项工作也得到了上海人工智能实验室张少霆研究员的大力支持,以及国家生物数据中心体系粤港澳大湾区节点,生物医学大数据操作系统 (Bio-OS) 的平台支持。
原文链接:https://doi.org/10.1186/s13059-024-03293-9
代码链接:https://github.com/FengAoWang/TMO-Net
李亦学,广州实验室特聘研究员,国家生物数据中心体系粤港澳大湾区节点平台首席科学家兼主任。研究方向为生物信息学和系统生物学、肿瘤基因组学、生物医学数据库构建和数据分析算法、疾病动物模型基因组学、精准医学。在Science,Nature,Nature Genetics,Nature Biotechnology,Lancet,Cancer Cell,Cell Stem Cell等杂志发表论文300篇以上,引用2.3万次以上。团队目前招收人工智能、生物信息学与智能医学大数据研究方向博士后若干名,欢迎感兴趣的博士加盟。
(模型框架示意图)
TMO-Net深度学习框架包括了单模态变分自编码器,跨模态变分自编码器,跨模态融合模块 (Cross Fusion Module) 。跨融合模块目的是将不同模态的嵌入融合到一个共同空间,通过使用专家乘积 (Product-of-Experts, PoE) 模块,有效地融合边缘变分后验的乘积并生成联合的潜在表征。在跨模态推断任务中,这些预训练得到的联合表征被用来重建缺失模态的数据,帮助实现样本的全模态表征。这一设计允许TMO-Net在面对缺失模态数据时仍能保持高效的样本表征学习和预测能力。作者从TCGA数据库中获取了32个泛癌多组学数据集,包含8174个样本,包含基因突变、mRNA表达、拷贝数变异 (CNV) 和DNA甲基化四种数据模态。在自监督预训练阶段,TMO-Net表现出了良好的肿瘤单/多组学样本表征能力和缺失数据的重构能力。在下游任务微调阶段,作者利用TMO-Net生成的多组学癌症样本表征,对模型参数进行微调以学习更加适应特定任务的表征,模型在多个下游肿瘤临床任务中展现了良好的适用性,包括乳腺癌亚型分类、癌症原发性与转移性预测、药物反应预测和癌症预后预测。
此外,作者还利用深度学习梯度归因算法 (Integrated Gradients) 来解释不同组学数据特征对肿瘤下游任务的影响。在乳腺癌亚型分类中,作者识别了 TM4SF5 、 RERG 、 NKX2-1 和 ESR1 等在乳腺癌分化、进展和癌症代谢起到重要作用的基因。在肿瘤转移分析中,研究人员确定了 TMC6 基因在肿瘤转移中的关键作用,并揭示了位于 KCNQ1 基因组区域的特定CpG探针:cg26879282、cg20751395和cg16778148对肿瘤转移的作用。作者还进一步探讨了 EGFR 基因表达在不同EGFR抑制剂药物的疗效的关联,以及不同基因特征对肿瘤预后的影响。该研究表明深度学习可解释性方法是进一步利用肿瘤人工智能模型进行疾病靶点解析的重要工具。
综上,该研究提出的TMO-Net模型框架证明了在大规模肿瘤多组学数据集上进行预训练可以增强肿瘤多组学和缺失组学数据的表征学习能力。该研究为未来开发生命科学多组学大模型奠定了基础,代表了肿瘤多组学数据人工智能研究领域的新进展。
中国科学院大学杭州高等研究院博士生、广州国家实验室实习生王烽傲、厦门大学硕士生庄震丰、中山大学第六附属医院高峰副研究员为该论文的共同第一作者。广州国家实验室李亦学研究员、刘俊伟博士后与厦门大学王连生教授为该论文的共同通讯作者。该项工作也得到了上海人工智能实验室张少霆研究员的大力支持,以及国家生物数据中心体系粤港澳大湾区节点,生物医学大数据操作系统 (Bio-OS) 的平台支持。
原文链接:https://doi.org/10.1186/s13059-024-03293-9
代码链接:https://github.com/FengAoWang/TMO-Net
李亦学,广州实验室特聘研究员,国家生物数据中心体系粤港澳大湾区节点平台首席科学家兼主任。研究方向为生物信息学和系统生物学、肿瘤基因组学、生物医学数据库构建和数据分析算法、疾病动物模型基因组学、精准医学。在Science,Nature,Nature Genetics,Nature Biotechnology,Lancet,Cancer Cell,Cell Stem Cell等杂志发表论文300篇以上,引用2.3万次以上。团队目前招收人工智能、生物信息学与智能医学大数据研究方向博士后若干名,欢迎感兴趣的博士加盟。
制版人:十一
版权声明:本文为“乐问号”作者或机构在乐问医学上传并发布,仅代表该作者或机构观点,不代表乐问医学的观点或立场,不能作为个体诊疗依据,如有不适,请结合自身情况寻求医生的针对性治疗。
链接:http://www.lewenyixue.com/2024/06/24/Genome%20Biol%20%7C%20%E6%9D%8E%E4%BA%A6%E5%AD%A6-%E7%8E%8B%E8%BF%9E/
THE END






赶快来坐沙发